Experiment tracking is essential in machine learning because it enables data scientists and researchers to effectively manage and reproduce their experiments. By tracking various aspects of an experiment, such as hyperparameters, model architecture, and training data, it becomes easier to understand and interpret the results. Experiment tracking also allows for better collaboration and knowledge sharing among team members, as it provides a centralized repository of experiments and their associated metadata. Additionally, tracking experiments helps in debugging and troubleshooting, as it allows for the identification of specific settings or conditions that led to successful or unsuccessful outcomes. Overall, experiment tracking plays a crucial role in ensuring transparency, reproducibility, and continuous improvement in machine learning workflows.
Now let's see how we can get all these benefits for free with PyTorch Tabular and Tensorboard (comes pre-installed with PyTorch Lightning). Although not as feature rich as Weights and Biases, Tensorboard is a classic offline tracking solution.
Importing the Library¶
from pytorch_tabular import TabularModel
from pytorch_tabular.models import (
CategoryEmbeddingModelConfig,
FTTransformerConfig,
TabNetModelConfig,
GANDALFConfig,
)
from pytorch_tabular.config import (
DataConfig,
OptimizerConfig,
TrainerConfig,
ExperimentConfig,
)
from pytorch_tabular.models.common.heads import LinearHeadConfig
Common Configs¶
data_config = DataConfig(
target=[
target_col
], # target should always be a list. Multi-targets are only supported for regression. Multi-Task Classification is not implemented
continuous_cols=num_col_names,
categorical_cols=cat_col_names,
)
trainer_config = TrainerConfig(
auto_lr_find=True, # Runs the LRFinder to automatically derive a learning rate
batch_size=1024,
max_epochs=100,
early_stopping="valid_loss", # Monitor valid_loss for early stopping
early_stopping_mode="min", # Set the mode as min because for val_loss, lower is better
early_stopping_patience=5, # No. of epochs of degradation training will wait before terminating
checkpoints="valid_loss", # Save best checkpoint monitoring val_loss
load_best=True, # After training, load the best checkpoint
)
optimizer_config = OptimizerConfig()
head_config = LinearHeadConfig(
layers="", # No additional layer in head, just a mapping layer to output_dim
dropout=0.1,
initialization="kaiming",
).__dict__ # Convert to dict to pass to the model config (OmegaConf doesn't accept objects)
EXP_PROJECT_NAME = "pytorch-tabular-covertype"
Category Embedding Model¶
model_config = CategoryEmbeddingModelConfig(
task="classification",
layers="1024-512-512", # Number of nodes in each layer
activation="LeakyReLU", # Activation between each layers
learning_rate=1e-3,
head="LinearHead", # Linear Head
head_config=head_config, # Linear Head Config
)
experiment_config = ExperimentConfig(
project_name=EXP_PROJECT_NAME,
run_name="CategoryEmbeddingModel",
log_target="tensorboard",
)
tabular_model = TabularModel(
data_config=data_config,
model_config=model_config,
optimizer_config=optimizer_config,
trainer_config=trainer_config,
experiment_config=experiment_config,
verbose=False,
suppress_lightning_logger=True,
)
tabular_model.fit(train=train, validation=val)
FT Transformer¶
model_config = FTTransformerConfig(
task="classification",
num_attn_blocks=3,
num_heads=4,
learning_rate=1e-3,
head="LinearHead", # Linear Head
head_config=head_config, # Linear Head Config
)
experiment_config = ExperimentConfig(
project_name=EXP_PROJECT_NAME,
run_name="FTTransformer",
log_target="tensorboard",
)
tabular_model = TabularModel(
data_config=data_config,
model_config=model_config,
optimizer_config=optimizer_config,
trainer_config=trainer_config,
experiment_config=experiment_config,
verbose=False,
suppress_lightning_logger=True,
)
tabular_model.fit(train=train, validation=val)
GANDALF¶
model_config = GANDALFConfig(
task="classification",
gflu_stages=10,
learning_rate=1e-3,
head="LinearHead", # Linear Head
head_config=head_config, # Linear Head Config
)
experiment_config = ExperimentConfig(
project_name=EXP_PROJECT_NAME,
run_name="GANDALF",
log_target="tensorboard",
)
tabular_model = TabularModel(
data_config=data_config,
model_config=model_config,
optimizer_config=optimizer_config,
trainer_config=trainer_config,
experiment_config=experiment_config,
verbose=False,
suppress_lightning_logger=True,
)
tabular_model.fit(train=train, validation=val)
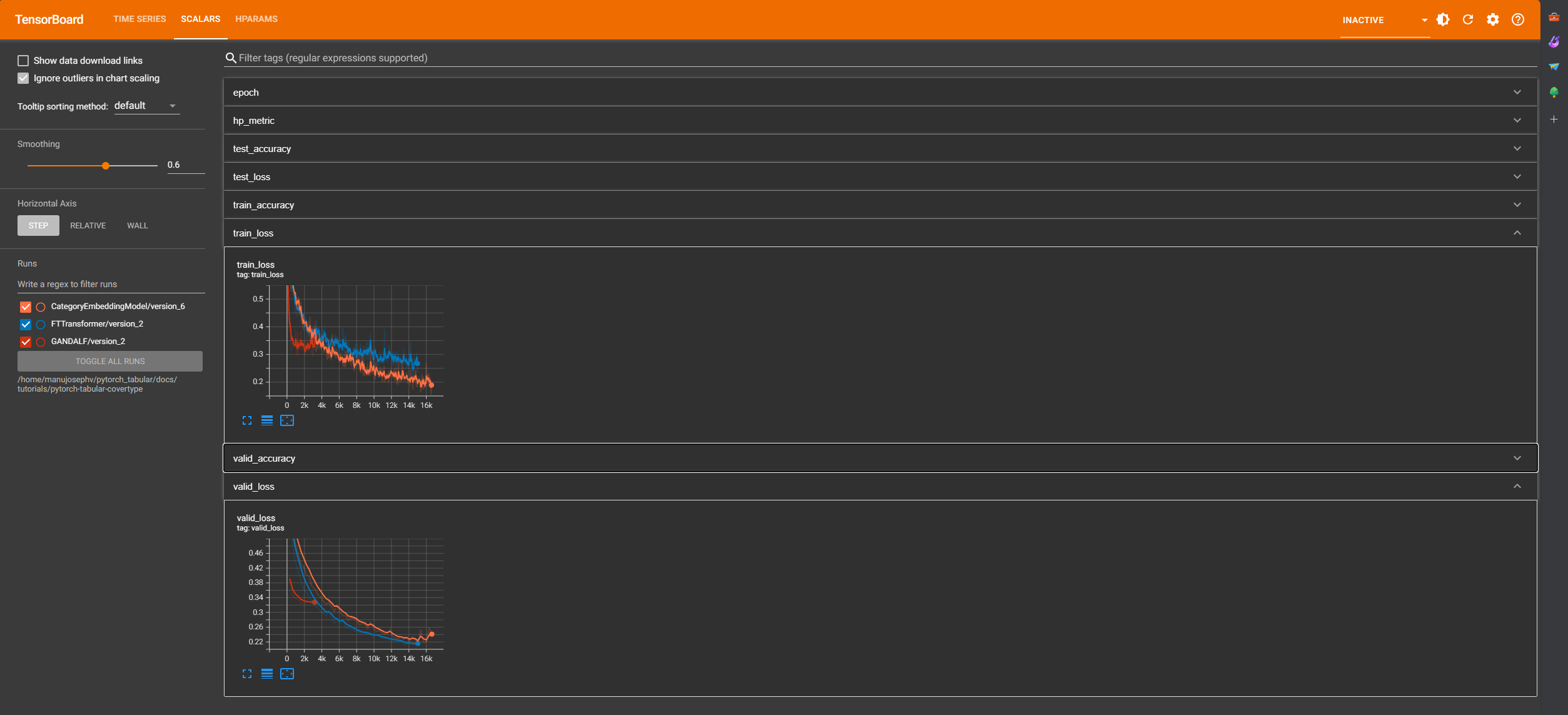
Accessing the Experiments¶
We can access the runs by following the steps below:
- Open a terminal and navigate to the directory where you saved the notebook.
- Run the following command:
tensorboard --logdir <project_name>--> In this case the command would betensorboard --logdir <project_name>This will start a local server with the runs in the provided folder and provide a link to access the Tensorboard UI. - Open the link in your browser.