Self-Supervised Models
An excerpt from the article by Yann LeCun and Ishan Mishra from Meta will serve as a good introduction here:
Supervised learning is a bottleneck for building more intelligent generalist models that can do multiple tasks and acquire new skills without massive amounts of labeled data. Practically speaking, it’s impossible to label everything in the world. There are also some tasks for which there’s simply not enough labeled data, such as training translation systems for low-resource languages.
As babies, we learn how the world works largely by observation. We form generalized predictive models about objects in the world by learning concepts such as object permanence and gravity. Later in life, we observe the world, act on it, observe again, and build hypotheses to explain how our actions change our environment by trial and error.
Common sense helps people learn new skills without requiring massive amounts of teaching for every single task. For example, if we show just a few drawings of cows to small children, they’ll eventually be able to recognize any cow they see. By contrast, AI systems trained with supervised learning require many examples of cow images and might still fail to classify cows in unusual situations, such as lying on a beach. How is it that humans can learn to drive a car in about 20 hours of practice with very little supervision, while fully autonomous driving still eludes our best AI systems trained with thousands of hours of data from human drivers? The short answer is that humans rely on their previously acquired background knowledge of how the world works.
How do we get machines to do the same?
We believe that self-supervised learning (SSL) is one of the most promising ways to build such background knowledge and approximate a form of common sense in AI systems.
SSL has been very successfully used in NLP (All the Large Language Models which create magic is learnt through SSL), and with some success in Computer Vision. But can we do that with Tabular data? The answer is yes.
A typical SSL workflow would have a large dataset without labels, and a smaller dataset with labels for finetuning.
- We start with Pre-training using unlabelled data
- Then we use the pre-trained model for a dowstream task like
regressionorclassificationi. We create a new model with the pretrained model as the backbone and a head for prediction
ii. We train the new model (finetune) on small labelled data
In PyTorch Tabular, the SSL model is implemented as an encoder-decoder model, i.e. we will have to define an encoder and a decoder using corresponding ModelConfig classes. The encoder is compulsory and the decoder if left empty will fall back to nn.Identity. This flexibility allows us to define SSL models where the learned feature representation is an intermediate layer or final layer. For the former (e.g. Denoising AutoEncoder), we can split the model at the intermediate layer and make the encoder output the intermediate layer and decoder transform the intermediate layer to the reconstruction.
The SSL model in PyTorch Tabular has the following components: 1. Embedding Layer - This is the part of the model which processes the categorical and continuous features into a single tensor. 2. Featurizer - This is the part of the model which takes the output of the embedding layer and does representation learning on it. The output is again a single tensor, which is the learned features from representation learning.
In PyTorch Tabular, an SSL model has to be inherited from SSLBaseModel which has similar function as the BaseModel. Any model imheriting SSLBaseModel needs to implement the following methods:
1. embedding_layer - A property method which returns the embedding layer
2. featurizer - A property method which returns the featurizer
3. _setup_loss - A method which sets up the loss function
4. _setup_metrics - A method which sets up the metrics
5. calculate_loss - A method which calculates the loss
6. calculate_metrics - A method which calculates the metrics
7. forward - A method which defines the forward pass of the model
8. featurize - A method which returns the learned features from the featurizer
We can choose the embedding layer, encoder, decoder etc. and their parameters using the model specific config classes.
Common Configuration¶
While there are separate config classes for each SSL model, all of them share a few core parameters in a SSLModelConfig class.
encoder_config: ModelConfig: The config of the encoder to be used for the model. Should be one of the model configs defined in PyTorch Tabulardecoder_config: Optional[ModelConfig]: The config of the decoder to be used for the model. Should be one of the model configs defined in PyTorch Tabular. If left empty, will be initialized asnn.Identity
Embedding Configuration
This is the same as Supervised Models. Refer to the Supervised Models documentation for more details.
Other Configuration
While supervised models had the loss and metrics as an argument in their configs, self-supervised models do not. This is because the loss functions and metrics are specific for different SSL model implementations and not normally interchangeable. So, we have to define the loss and metrics in the model itself. The loss and metrics are defined in the _setup_loss and _setup_metrics methods respectively.
-
learning_rate: float: The learning rate of the model. Defaults to 1e-3. -
seed: int: The seed for reproducibility. Defaults to 42
Usage:¶
These are the main steps to use a self-supervised model in PyTorch Tabular:
- Define all the configs and initialize pytorch_tabular.TabularModel
- Pretrain the model using un-labelled data with pytorch_tabular.TabularModel.pretrain
- Create a new fine-tune model with the pretrained weights using pytorch_tabular.TabularModel.create_finetune_model
- Finetune the model with labelled data using pytorch_tabular.TabularModel.finetune
For a more detailed and practical approach, refer to the SSL Tutorial
Available Models¶
Now let's look at a few of the different models available in PyTorch Tabular and their configurations. For a complete list of implemented models:
>>> [cl for cl in dir(pytorch_tabular.ssl_models) if "config" in cl.lower()]
['DenoisingAutoEncoderConfig']
Denoising AutoEncoder Model¶
PyTorch Tabular has provided the Denoising AutoEncoder implementation inspired from https://github.com/ryancheunggit/tabular_dae. Let's see how we can use that.
A Denoising AutoEncoder has the below architecture (Source):
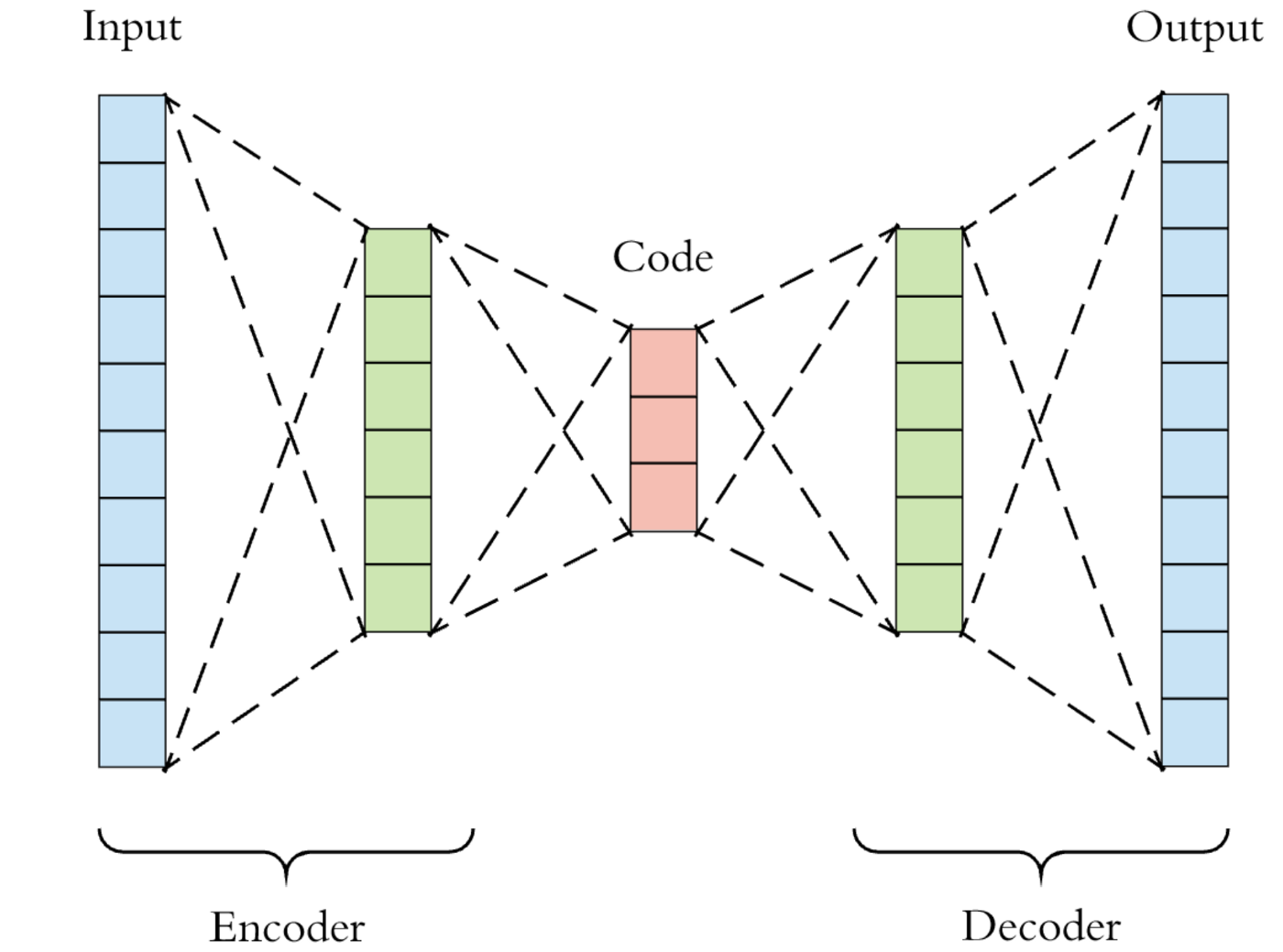
We corrupt the input on the left and we ask the model to learn to predict the orginal, denoised input. By this process, the network is forced to learn a compressed bottleneck (labelled code) which captures most of the characteristics of the input data, i.e. a robust representation of the input data.
In the DenoisingAutoencoder implementation in PyTorchTabular, the noise is introduced in two ways:
1. swap - In this strategy, noise is introduced by replacing a value in a feature with another value of the same feature, randomly sampled from the rest of the rows.
zero- In here, noise is introduced by just replacing the value with zero.
In addition to that, we also can set noise_probabilities, with which we can define the probability with which noise will be introduced to a feature. We can set this parameter as a dictionary of the form, {featurename: noise_probability}. Or we can also set a single probability for all the features easily by using default_noise_probability
Now once we have this robust representation, we can use this representation in other downstream tasks like regression or classification.
All the parameters have intelligent default values. Let's look at few of them:
noise_strategy: str: The strategy to introduce noise. Can be one ofswaporzero. Defaults toswapnoise_probabilities: Optional[Dict[str, float]]: The probability with which noise will be introduced to a feature. Can be a dictionary of the form,{featurename: noise_probability}. Or can be set to a single probability for all the features easily by usingdefault_noise_probability. Defaults to None
For a complete list of parameters refer to the API Docs
pytorch_tabular.ssl_models.DenoisingAutoEncoderConfig